
Report of the STSM by Stanislava Gardašević at University of Malta
Visit to Milena Dobreva, 2016-03-16 to 2016-03-25 University Malta
One of the major roles of libraries and librarians is to offer to the public new ways to store and discover information, as nowadays this public has become very active in generating knowledge and data. Therefore we ought to offer new services and host Citizen Science projects. In order to stimulate the public to contribute the data and participate actively, we should offer them user friendly and intuitive visualisation tools and software.
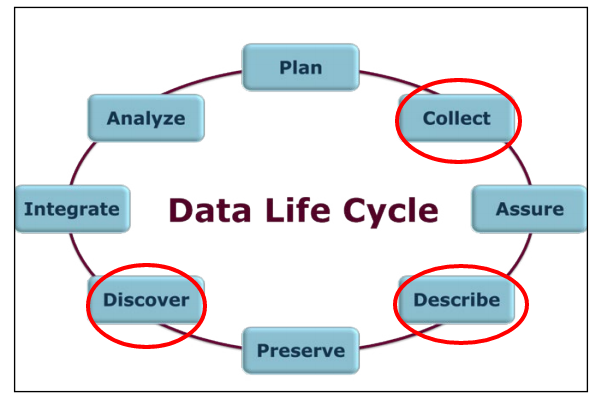
My motivation for doing this STSM was to explore the requirements that are prerequisite in order to achieve successful visualisation solutions for end users, especially when it comes to two essential parts of the „data life cycle model“ [1] of Citizen Science projects –data collection on the one hand and data discovery and reuse on the other, both of which are dependent of the data description (as illustrated on the image). Furthermore it explored how this could be achieved through particular knowledge organisation systems- ontologies .
Thanks to supervision of prof. Milena Dobreva from University of Malta, Faculty of Media and Knowledge Science, I was introduced to the main issues of this topic as well as to plethora of literature pertinent to it. After careful survey of selected articles and several cases of sucessful Citizen Science projects I was able to identify necessities and good practices when it comes to these two aspects of data cycle and how it can be related to semantical systems.
One of the key requirements for the successful visualisation of these stages is to establish a solid data model in the first place- as data quality is critical issue for every Citizen Science project. Also, it is strongly recommended to use taxonomies and codes as much as possible- in order to control the entry of data by different users and to make its components as explicit as possible. Finally, the model should contain mutual relations and associations among data components. This practice should ensure the basis for input (usually performed via collection protocols), and afterwords for establishing the ways for access and reuse (via search, browse, through map interface and other options). Also, literature outlines as a crucial component the availability of support for the citizens in these process (manuals, tutorials, online help), validation and feedback on the collected data and finally to enable clear communication protocols among users of the system [1, 2, 3].
Even though one would assume this would be a good place to use folksonomies – collaboratively created ontologies of a certain domain, this however may not be a satisfying solution because of the variety of users and their different level of expertise. On the other hand, others recommend usage ontologies (especially instance-based, and not class-based) in order to develop conceptual model of a crowdsourcing system, and in this case it may be usefull to allow users to to report attributes of instances of the domain covered [4]. When applications use ontology rules, they can realize powerful reasoning over annotated data, which could be useful for data analysis and consequentially visualisation. Although ontologies could be used as a start data model, only few projects are done this way and those are mostly regarding collection of geospatial data. Currently, Citizen Science projects that are utilising semantical annotations are usually doing this in cases when data collection is performed via social networks, or by implementing the semantic layer after the collection process- so called semantic analysis and enrichment on the collected and not completely structured data- in order to make it more meaningful and usable, both for human and machine clients. Data that is semantically anotated is esier to integrate, interpret, and combine with other databases, knowledge bases and advanced computing capabilities [5].
This STSM has helped me to expand the knowledge on the requirements and specifics of different stages of Citizen Science project practices and infrastrucures, but also to outline recommendations that will be used in my further exploration of this topic. Furthermore, we have established the plan to develop this survey of literature and current practices into a paper that should be presented at the final conference related to KNOEeSCAPE COST Action.
Finally, during my stay in Malta I was invited to give a lecture „Experiences with metadata delivery to Europeana from National Library of Serbia“ to master students of Library Information and Archive Science Department at University of Malta, which was attended also by representatives of public and corporate institutions, as well as Library Association. The host organised plethora of interesting and useful meetings for knowledge and experience exchange with professionals from National Archive of Malta and National Library of Malta. Since I am also coming from the national level institution, it was very valuable to discuss about the challenges and practices we have in our cases, especially regarding implementation of metadata formats. Also, we had a very fruitful meeting at the Malta University Library with staff in charge of different tasks, and an especially interesting session with Mary Samut-Tagliaferro, the library manager for special collections of this institutions, who was interested in recommendations when it comes to cooperation with Europeana and other processes regarding digitisation.
I would like to express my warmest gratitude to the host department and especially Prof. Milena Dobreva for all the support, as well as to the KNOWeSCAPE Program for enabling me to do this research.
Stanislava Gardašević
National Library of Serbia
Department for Digital Library Development and Microfilming
http://nb.rs
http://digitalna.nb.rs
http://velikirat.nb.rs/
References:
[1] DataONE Public Participation in Scientific Research Working Group. 2013. Data Management Guide for Public Participation in Scientific Research. Image from page 2. Available at:
https://www.dataone.org/sites/all/documents/DataONE-PPSR-DataManagementGuide.pdf
[2] The Cornell Lab of Ornithology. Citizen Science Central. Toolkit Steps. Available at: http://www.birds.cornell.edu/citscitoolkit/toolkit/steps/train/train-participants
[3] Bonney R, Cooper CB, Dickinson J, Kelling S, Phillips T, et al. 2009. Citizen science: a developing tool for expanding science knowledge and scientific literacy. BioScience 59:977-84. DOI: 10.1525/bio.2009.59.11.9
[4] Lukyanenko, R., Parsons, J. 2012. Conceptual Modeling Principles for Crowdsourcing. Proceedings of the 1st International Workshop on Multimodal Crowd Sensing. DOI: 10.1145/2390034.2390038
[5] Sheth, A. P. 2009. Citizen Sensing, Social Signals, and Enriching Human Experience. IEEE Internet Computing, 13 (4), 87-92. DOI: 10.1109/MIC.2009.77


