
This report is also available at http://dans-labs.github.io/RESplorer/ together with the source code of RESplorer.
About RESplorer
RESplorer is the outcome of Christophe Guéret (@cgueret) experiencing with Acropolis during a KNOWeSCAPE Short Term Scientific Mission (STSM) at the BBC Media Centre between June 1th and June 5th 2015.
Acropolis is at the heart of “Research & Education Space” (RES), a joint project of the BCC, Jisc and the British Universities Film & Video Council (BUFVC). The aim of this project is to bring as much as possible of the UK’s publicly-held archives, and more besides, to learners and teachers across the UK. Under the hood Acropolis collects, indexes and organises rich structured data about those archive collections published as Linked Open Data (LOD) on the Web.
Data Archiving and Networked Services (DANS) is a digital preservation institute of the Dutch KNAW which takes care of data from the humanities and social sciences. It is the host of several datasets, some of them published as Linked Open Data, and works closely with other institutions publishing structured data (Europeana, Huygens Institute, IISH, Open Cultuur, …). In particular DANS recently got involved into the design of a general architecture for sharing data among researchers from the digital humanities called CLARIAH.
The objectives of this STSM where to look at giving an answer to the following questions:
- How much of the architectural design of Acropolis can be ported into CLARIAH, and vice-versa ?
- Can the content of DANS archives be incorporated in RES ?
- Could DANS contribute to spreading the usage of the content of RES from within the Netherlands ?
- How can the output created by RES, or CLARIAH, be visualised in order to provide insights into its content ?
Study outcome
RESplorer is a script that uses the API from Acropolis to create an overview of the content of the platform. As of June 4th, the ouput of the script was as follows:
Total number of entities :
90200
Total number of triples :
{'all': 4032105, 'second': 545437}
Data import chains :
dbpedia.org -> acropolis.org.uk
www.ordnancesurvey.co.uk -> acropolis.org.uk
rdf.freebase.com -> acropolis.org.uk
billings.acropolis.org.uk -> acropolis.org.uk
rdf.insee.fr -> acropolis.org.uk
fp.bbc.co.uk -> acropolis.org.uk
sws.geonames.org -> acropolis.org.uk
sws.geonames.org -> data.nytimes.com
data.nytimes.com -> acropolis.org.uk
www.bbc.co.uk -> acropolis.org.uk
Instances per type :
73284 : http://www.w3.org/2003/01/geo/wgs84_pos#SpatialThing
2847 : http://purl.org/NET/c4dm/event.owl#Event
10156 : http://www.w3.org/2004/02/skos/core#Concept
34 : http://purl.org/dc/dcmitype/Collection
1764 : http://purl.org/vocab/frbr/core#Work
2081 : http://xmlns.com/foaf/0.1/Document
34 : http://rdfs.org/ns/void#Dataset
Instances per source :
71749 : sws.geonames.org
11713 : data.nytimes.com
90200 : acropolis.org.uk
6760 : billings.acropolis.org.uk
This indicates that 90200 entities of various types are present in the index. The two most represented types being SpatialThings (73k) and Concepts (10k). The data import chains show that most of the time the data sources are exposing their own data with the exception of data.nytimes.com whish re-publishes the data from sws.geonames.org . More accurately, it is observed that data.nytimes.com contains triples using subjects based in sws.geonames.org. This could be new triples re-using those subjects or triples copy&pasted from Geonames. A quick manual checked confirmed that data.nytimes.com followed the current trend of not re-using URIs and created their own, all the content found using sws.geonames.org as a subject is thus copied from sws.geonames.org. The issue this represents is that those triples may be out of date and in fact several false assertions which are now corrected in Geonames are still present in the data fetched from data.nytimes.com. The number of “second hand” triples (545437 in the current count) measures that risk. It currently amounts to 13% of the data found in Acropolis.
The script also produces a graph showing the complexity of the dataset in terms of data sources being used. Here is how the graph is created:
- One node per combination of instance type and list of data sources used for describing entities
- Nodes color = type of instances
- Nodes size = number of instances matching that combination of type + data sources (represented on a log scale)
- Edges thickness = Jaccard distance between the set of data sources for the two connected nodes
As of June 4th, this is how the graph is rendered by Graphviz :
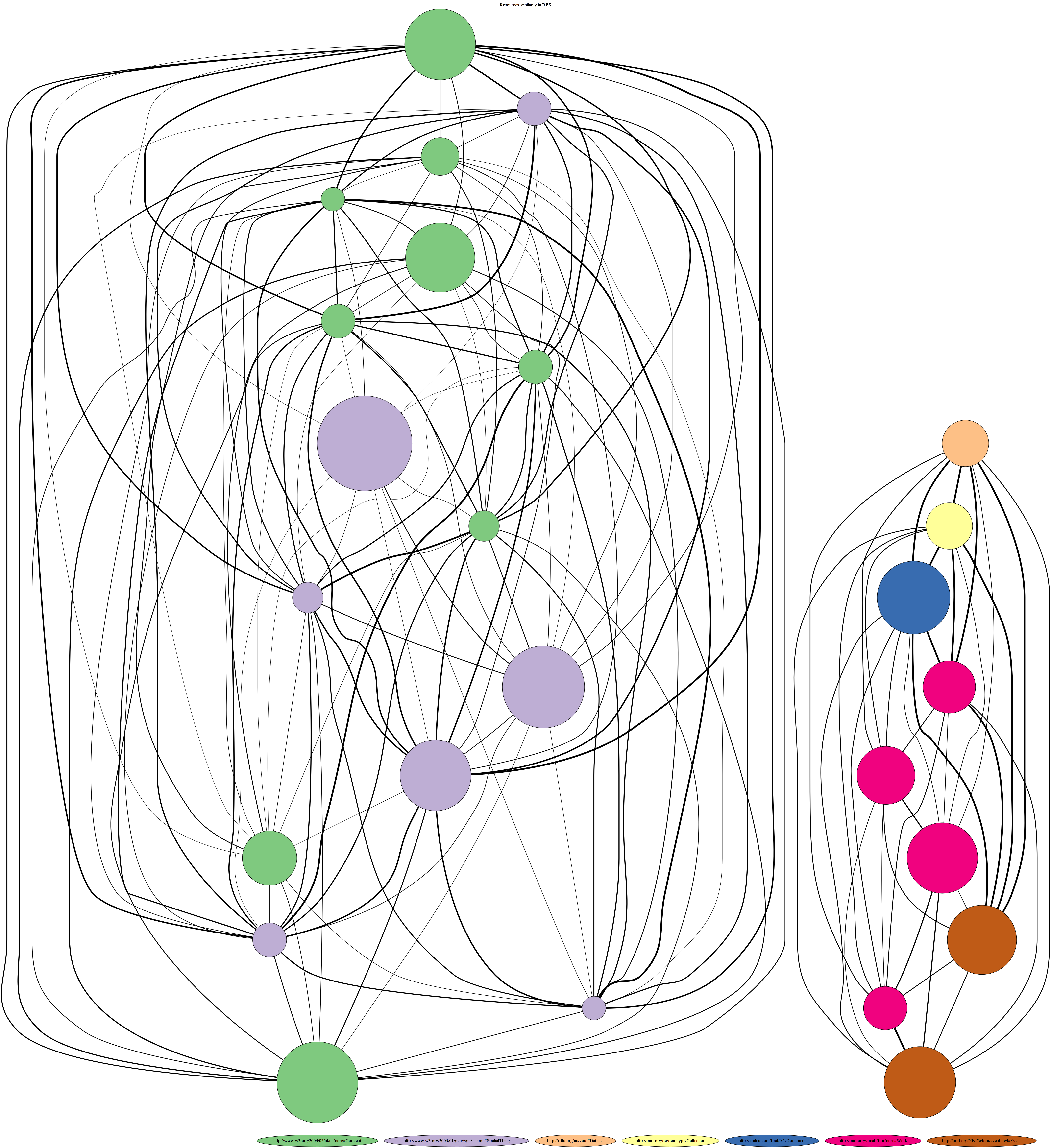
Representation of the complexity of the data in Acropolis
Some interesting points shown in that graph:
- Concepts and Places have similar data sources
- Dataset, Collections, Documents, Works and Event have similar data sources too
- The two groups don’t share anything
- The majority of the spatial entities are described by a sources hardly anyone else re-use (big purple circle in the middle with very thin connections)
- All the datasets are described using the same set of sources (one node of that color), same for all the collections and documents
Next steps
During this study Acropolis proved to be a stable and fast APIs with a growing content, there were new entities every day. Part of the future work include ensuring that the content created by CLARIAH can be ingested into RES and planning a joint hackathon some time in 2016 to get potential users play with the data. There is also much collaboration expected to take place in the context of the newly created W3C community group Exposing and Linking cultural heritage data.
Contact
For more information about this project and related activities get in touch with either Christophe Guéret (@cgueret) or Andrew Dudfield (@mr_dudders).


